
※Convolution 컨볼루션
- cnn : 분류 및 검출에 많이 사용된다.
import numpy as np
import matplotlib.pyplot as plt
np.convolve([1,2,3,],[1,1,1]) # (데이터, 필터)→ array([1, 3, 6, 5, 3])
* convolve : 합성곱
# [0,0,1,2,3,0,0] # 좌우에 0 패딩을 2번 붙였다
np.sum(np.array([0,0,1]) * np.array([1,1,1]))→ 1
# 패딩(padding) : convolution 레이어의 출력 데이터가 줄어드는 것을 방지하는 방법
# - 입력 데이터의 외각에 지정된 픽셀만큼 특정 값으로 채워 넣는 것
# - 필터가 하나 일때는 패딩이 필요가 없음
np.sum(np.array([0,1,2]) * np.array([1,1,1]))→ 3
# [0,0,1,2,3,0,0] # 좌우에 0 패딩을 2번 붙였다
np.sum(np.array([1,2,3]) * np.array([1,1,1]))→ 6
# [0,0,1,2,3,0,0] # 좌우에 0 패딩을 2번 붙였다
np.sum(np.array([2,3,0]) * np.array([1,1,1]))→ 5
# [0,0,1,2,3,0,0] # 좌우에 0 패딩을 2번 붙였다
np.sum(np.array([3,0,0]) * np.array([1,1,1]))→ 3
# 중간에 1씩 떨어질때 값이 떨어지는 부분을 찾아라
np.convolve([1,2,3,4,5,4,5,6,7,8,7,8,9,10,11,10,11,12],[-1,0,1,0]) # (데이터, 필터)→ array([-1, -2, -2, -2, -2, 0, 0, -2, -2, -2, 0, 0, -2, -2, -2, 0, 0, -2, 11, 12, 0])
np.sum(np.array([0,0,0,1]) * np.array([-1,0,1,0]))→ 0
# 중간에 1씩 떨어질때 값이 떨어지는 부분을 찾아라
# full : 기본, CNN에서 사용하지 않음
# same : 필요한 경우 패딩을 사용하여 src, out의 길이가 같게 만듬
# valid : 패딩 사용 안함
2*np.convolve([1,2,3,4,5,4,5,6,7,8,7,8,9,10,11,10,11,12],[-0.5,0.5,0],'same') # (데이터, 필터)→ array([-1., -1., -1., -1., 1., -1., -1., -1., -1., 1., -1., -1., -1., -1., 1., -1., -1., 12.])
src = np.cos(np.arange(-3, 3 ,0.1))
plt.plot(src)
src = np.sin(np.arange(-10, 10, 0.1))
plt.plot(src, label='src')
# dst = np.convolve(src,[-1,0,1,2,1,0,-1], 'same') # 값이 올라갔다 내려오는 위치 찾기
dst = np.convolve(src,[3,2,1,0,-1,-2,-3], 'same') # 값이 떨어지는 위치 찾기
plt.plot(dst, label='dst')
plt.legend()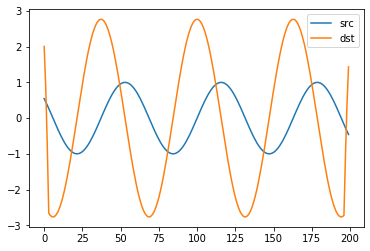
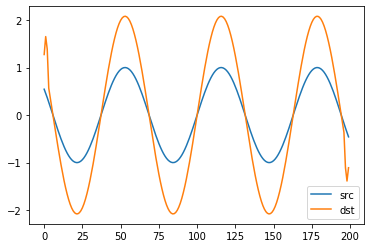
# full : 기본, CNN에서 사용하지 않음
# same : 필요한 경우 패딩을 사용하여 src, out의 길이가 같게 만듬
# valid : 패딩 사용 안함
x = [1,2,3,4,5]
full = np.convolve(x, [1,2])
same = np.convolve(x, [1,2], 'same') #(데이터, 필터)
valid = np.convolve(x, [1,2], 'valid')
full, same, valid→ (array([ 1, 4, 7, 10, 13, 10]), array([ 1, 4, 7, 10, 13]), array([ 4, 7, 10, 13]))
import tensorflow as tf
from tensorflow import keras# tensorflow 이미지 format(m,h,w,c), 필터 format(h,w,c,m), 조건 : c가 같아야 한다.
input = np.array([1,2,3,4,5,6]).reshape((1,2,3,1)).astype(np.float32)
filter = np.array([1,2,3,4]).reshape((2,2,1,1)).astype(np.float32)
out = tf.nn.conv2d(input, filter, padding='VALID')
# reshape :(데이터 갯수, 높이, 너비, 채널)→ astype() = Array 전체 형을 바꾸고 싶을때 사용
sess = tf.Session()
sess.run(out)→ array([[[[37.], [47.]]]], dtype=float32)
* run : 연산 그래프를 실행하려 할때는 Session 객체의 run() 메소드 사용
# 10 x 10 x 1 (h,w,c) 흑백 이미지를 2장 만들어서 임의의 위치에 '+' 패턴을 그려서 필터로 찾아보자
y = np.array([[[3,3],[7,7]],[[2,3],[5,5]]])
x = np.zeros((2, 10, 10, 1)) # 2장의 흑백 이미지 mhwc-포맷
x += np.random.rand(2, 10, 10, 1) # 노이즈
for i in range(len(y)):#2
label = y[i]
for j in range(len(label)):
point = label[j]
px = point[0]
py = point[1]
x[i, py-1:py+2, px] += 1
x[i, py, px-1:px+2] += 1
plt.imshow(x[1,:,:,0], cmap='gray')
# x.shape, y.shape
# convolution 의 특징 : 이동 불변성 shift invariant, 가중치 공유 weight sharing
filter = np.array([0,1,0,1,1,1,0,1,0], dtype=np.float32).reshape((3,3,1,1)) # 필터 : HWCM 포맷
out = tf.nn.conv2d(x, filter, padding='SAME') # SAME(90%) or VALID(상하좌우 값 1개씩 빠집니다.)
# out = tf.nn.max_pool(out, 3, 3, padding="SAME")
sess = tf.Session()
response = sess.run(out)
plt.imshow(response[0,:,:,0], cmap='gray') # 패턴을 그린 위치에 가장 큰 값이 나타납니다.
from sklearn.datasets import load_digits
data = load_digits()
x = data.images
y = data.target
x.shape, y.shape→ ((1797, 8, 8), (1797,))
* from sklearn.datasets import load_digits : 0부터 9까지의 숫자를 손으로 쓴 이미지 데이터. load_digits() 명령으로 로드한다. 각 이미지는 0부터 15까지의 명암을 가지는 8x8=64픽셀 해상도의 흑백 이미지이다.
from tensorflow import kerasmodel = keras.Sequential()
model.add(keras.layers.Input((8,8,1)))
model.add(keras.layers.Conv2D(32, [3,3], padding="same")) # 필터 갯수 32, 크기 [3,3]
model.add(keras.layers.MaxPool2D((2,2), padding="same"))
model.add(keras.layers.Conv2D(64, [3,3], padding="same"))
model.add(keras.layers.MaxPool2D((2,2), padding="same"))
model.add(keras.layers.Flatten()) # 1D로 모양 바꾸기
model.add(keras.layers.Dense(10, activation = keras.layers.Softmax())) # 클래스가 10개이므로
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(),metrics=['accuracy'])* Conv2D:
- 첫번째 인자 : 컨볼루션 필터의 수 입니다.
- 두번째 인자 : 컨볼루션 커널의 (행, 열) 입니다.
- padding : 경계 처리 방법을 정의합니다.
- ‘valid’ : 유효한 영역만 출력이 됩니다. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작습니다.
- ‘same’ : 출력 이미지 사이즈가 입력 이미지 사이즈와 동일합니다.
- input_shape : 샘플 수를 제외한 입력 형태를 정의 합니다. 모델에서 첫 레이어일 때만 정의하면 됩니다.
- (행, 열, 채널 수)로 정의합니다. 흑백영상인 경우에는 채널이 1이고, 컬러(RGB)영상인 경우에는 채널을 3으로 설정합니다.
- activation : 활성화 함수 설정합니다.
- ‘linear’ : 디폴트 값, 입력뉴런과 가중치로 계산된 결과값이 그대로 출력으로 나옵니다.
- ‘relu’ : rectifier 함수, 은익층에 주로 쓰입니다.
- ‘sigmoid’ : 시그모이드 함수, 이진 분류 문제에서 출력층에 주로 쓰입니다.
- ‘softmax’ : 소프트맥스 함수, 다중 클래스 분류 문제에서 출력층에 주로 쓰입니다.
* MaxPool2D : 컨볼루션 레이어의 출력 이미지에서 주요값만 뽑아 크기가 작은 출력 영상을 만듭니다. 이것은 지역적인 사소한 변화가 영향을

미치지 않도록 합니다.
* Flatten : 1차원으로 바꿔주는 레이어
CNN에서 컨볼루션 레이어나 맥스풀링 레이어를 반복적으로 거치면 주요 특징만 추출되고, 추출된 주요 특징은 전결합층에 전달되어 학습됩니다. 컨볼루션 레이어나 맥스풀링 레이어는 주로 2차원 자료를 다루지만 전결합층에 전달하기 위해선 1차원 자료로 바꿔줘야 합니다. 이 때 사용되는 것이 플래튼 레이어입니다.
x_4d = np.expand_dims(x, -1)
model.fit(x_4d, y, epochs=10)
model.summary()Epoch 1/10 1797/1797 [=============================] - 1s 305us/sample - loss: 0.9667 - acc: 0.7284 Epoch 2/10 1797/1797 [=============================] - 0s 174us/sample - loss: 0.2309 - acc: 0.9377
Epoch 9/10 1797/1797 [=============================] - 0s 188us/sample - loss: 0.0084 - acc: 0.9994 Epoch 10/10 1797/1797 [=============================] - 0s 192us/sample - loss: 0.0188 - acc: 0.9944
| Layer (type) | Output Shape | Param # |
| conv2d (Conv2D) | (None, 8, 8, 32) | 320 |
| max_pooling2d (MaxPooling2D) | (None, 4, 4, 32) | 0 |
| conv2d_1 (Conv2D) | (None, 4, 4, 64) | 18496 |
| max_pooling2d_1 (MaxPooling2D) | (None, 2, 2, 64) | 0 |
| flatten (Flatten) | (None, 256) | 0 |
| dense (Dense) | (None, 10) | 2570 |
|
Total params: 21,386 Trainable params: 21,386 Non-trainable params: 0 |
||
'Deep learning > Code' 카테고리의 다른 글
| keras_logistic_regression_expert (0) | 2020.01.29 |
|---|---|
| gradientDescent (0) | 2020.01.29 |
| Multi-class (0) | 2020.01.29 |
| 분류2 classification (0) | 2020.01.28 |
| 분류 classification (0) | 2020.01.23 |