
통계적 언어모델은 전통적인 접근 방법이다.
1. 조건부 확률
조건부 확률은 두 확률 P(A), P(B)에 대해서 아래와 같은 관계를 갖는다.
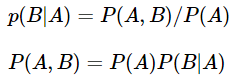
4개의 확률이 조건부 확률의 관계를 가질 때는 아래와 같이 표현 할 수 있다.

이를 조건부 확률의 연쇄 법칙(chain rule)이라고 한다.
다음은 n개에 대해서 일반화를 해본다.

조건부 확률에 대한 정의를 통해 문장의 확률을 구할 수 있다.
2. 문장에 대한 확률
문장 'An adorable little boy is spreading smiles'의 확률
P(An adorable little boy is spreading smiles)를 식으로 표현해봅시다.
조건부 확률의 일반화 식을 문장의 확률 관점에서 다시 적어보면 문장의 확률은 각 단어들이 이전 단어가 주어졌을 때 다음 단어로 등장할 확률의 곱으로 구성된다.

위의 문장에 해당 식을 적용해 보면 다음과 같다.

문장의 확률을 구하기 위해서 각 단어에 대한 예측 확률들을 곱한다.
3. 카운트 기반의 접근
문장의 확률을 구하기 위해 다음 단어에 대한 예측 확률을 모두 곱한다.
SLM은 이전 단어로부터 다음 단어에 대한 확률을 구할때 카운트에 기반하여 확률을 계산 한다.
An adorable little boy가 나왔을 때, is가 나올 확률인 P(is|An adorable little boy)를 구해보면 다음과 같다.
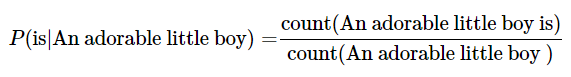
예를 들어 기계가 학습한 코퍼스 데이터에서 An adorable little boy가 100번 등장했는데 그 다음에 is가 등장한 경우는 30번이라고 할때 이 경우 P(is|An adorable little boy)는 30%이다.
4. 카운트 기반 접근의 한계 - 희소 문제(Sparsity Problem)
언어 모델은 실생활에서 사용되는 언어의 확률 분포를 근사 모델링 한다.
현실에서 An adorable little boy가 나왔을 때 is가 나올 확률이라는 것이 존재할때, 이를 실제 자연어의 확률 분포, 현실에서의 확률 분포라고 명칭한다면, 기계에게 많은 코퍼스를 훈련시켜서 언어 모델을 통해 현실에서의 확률 분포를 근사하는 것이 언어 모델의 목표이다.
카운트 기반으로 접근하려고 한다면 기계가 훈련하는 데이터는 방대한 양이 필요하다.

예를 들어 P(is|An adorable little boy)를 구하는 경우에서 기계가 훈련한 코퍼스에 An adorable little boy is라는 단어 시퀀스가 없었다면 이 단어 시퀀스에 대한 확률은 0이 된다.
또는 An adorable little boy라는 단어 시퀀스가 없었다면 분모가 0이 되어 확률은 정의되지 않는다.
그렇다고 코퍼스에 단어 시퀀스가 없다고해서 이 확률이 0 또는 정의되지 않는 확률이라고 하는 것이 정확한 모델링 방법이라고는 할순 없다.
이와 같이 충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제를 희소 문제(sparsity problem)라 한다.
위 문제를 완화하는 방법으로 다음 챕터에서 배우는 n-gram이나 이 책에서 다루지는 않지만 스무딩이나 백오프와 같은 여러가지 일반화(generalization) 기법이 존재한다.
하지만 희소 문제에 대한 근본적인 해결책은 되지 못하였다.
결국 이러한 한계로 인해 언어 모델의 트렌드는 통계적 언어 모델에서 인공 신경망 언어 모델로 넘어가게 된다.
정리:
1. 4개의 확률이 조건부 확률의 관계를 가지는 것을 조건부 확률의 연쇄 법칙(chain rule)이라고 한다.
2. 문장의 확률을 구하기 위해서 각 단어에 대한 예측 확률들을 곱한다.
3. SLM은 이전 단어로부터 다음 단어에 대한 확률을 구할때 카운트에 기반하여 확률을 계산 한다.
4. 충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제를 희소문제(sparsity problem)라 한다.
5. 통계적 언어 모델의 희소문제 같은 한계로 인해 모델의 트렌드는 인공 신경망 언어 모델로 넘어가게 된다.
'Deep learning > NLP(자연어처리)' 카테고리의 다른 글
| 펄플렉서티(Perplexity) (0) | 2020.02.27 |
|---|---|
| 한국어에서의 언어 모델(Language Model for Korean Sentences) (0) | 2020.02.27 |
| N-gram 언어 모델(N-gram Language Model) (0) | 2020.02.27 |
| 언어 모델(Language Model) (0) | 2020.02.26 |
| 자연어 처리(불용어) (0) | 2020.02.26 |