
문서의 유사도를 구하는 일은 자연어 처리의 주요 주제 중 하나이다.
사람들이 인식하는 문서의 유사도는 주로 문서들 간에 동일한 단어 또는 비슷한 단어가 얼마나 공통적으로 많이 사용되었는지에 의존한다.
기계또한 마찬가지로 기계가 계산하는 문서의 유사도의 성능은 각 문서의 단어들을 어떤 방법으로 수치화 하여 표현했는지(DTM, Word2Vec 등), 문서 간의 단어들의 차이를 어떤 방법(유클리드 거리, 코사인 유사도 등)으로 계산했는지에 달려있다.
1. 코사인 유사도
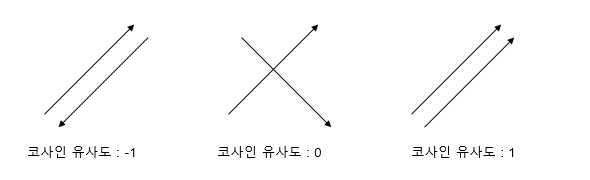
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다.
두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖게 된다.
두 벡터 A, B에 대해서 코사인 유사도는 식으로 표현하면 다음과 같다.

문서 단어 행렬이나 TF-IDF 행렬을 통해서 문서의 유사도를 구하는 경우에는 문서 단어 행렬이나 TF-IDF 행렬이 각각의 특징 벡터 A, B가 된다.
그렇다면 문서 단어 행렬에 대해서 코사인 유사도를 구해보는 간단한 예제를 보겠다.
문서1 : 저는 사과 좋아요
문서2 : 저는 바나나 좋아요
문서3 : 저는 바나나 좋아요 저는 바나나 좋아요
위의 세 문서에 대해서 문서 단어 행렬을 만들면 이와 같다.
| - | 바나나 | 사과 | 저는 | 좋아요 |
| 문서1 | 0 | 1 | 1 | 1 |
| 문서2 | 1 | 0 | 1 | 1 |
| 문서3 | 2 | 0 | 2 | 2 |
다음은 파이썬에서 Numpy를 이용한 코사인 유사도를 구하는 방법이다.
# 코사인 유사도를 계산하는 함수
from numpy import dot
from numpy.linalg import norm
import numpy as np
def cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))# 문서1, 문서2, 문서3에 대해 각각 BoW를 만듬. doc1=np.array([0,1,1,1]) doc2=np.array([1,0,1,1]) doc3=np.array([2,0,2,2])
# 각 문서에 대한 코사인 유사도를 계산 print(cos_sim(doc1, doc2)) #문서1과 문서2의 코사인 유사도 print(cos_sim(doc1, doc3)) #문서1과 문서3의 코사인 유사도 print(cos_sim(doc2, doc3)) #문서2과 문서3의 코사인 유사도
0.67 0.67 1.00
* 정리:
1. 코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다.
2. 코사인 유사도는 -1이상 1이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단 할 수 있다.
'Deep learning > NLP(자연어처리)' 카테고리의 다른 글
| 워드 임베딩(Word Embedding) (0) | 2020.03.08 |
|---|---|
| TF-IDF(Term Frequency-Inverse Document Frequency) (0) | 2020.03.03 |
| 문서 단어 행렬(Document-Term Matrix, DTM) (0) | 2020.03.03 |
| Bag of Words(BoW) (0) | 2020.03.03 |
| 카운트 기반의 단어 표현(Count based word Representation) (0) | 2020.03.02 |