
※ IRIS 데이터 분류
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import optimizers
from tensorflow.keras.layers import Dense!wget https://raw.githubusercontent.com/dhrim/oss_university/master/material/iris.csv!head iris.csv
!wc iris.csviris = pd.read_csv("iris.csv")
iris.head()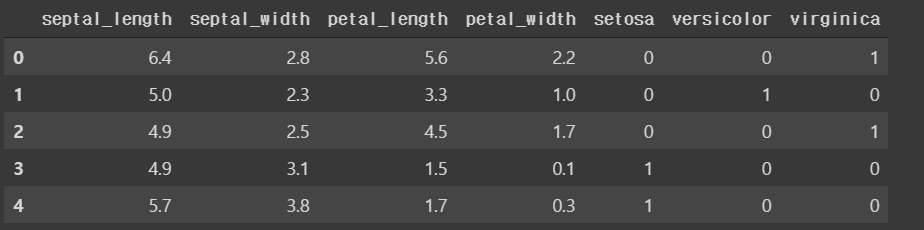
iris.info()data = iris.to_numpy()
print(data.shape)
print(data[:5])x = data[:,:4]
y = data[:,4:]
split_index = 100
train_x, test_x = x[:split_index], x[split_index:]
train_y, test_y = y[:split_index], y[split_index:]model = keras.Sequential([
keras.layers.Dense(10, activation='relu', input_shape=(4,)),
keras.layers.Dense(10, activation='relu'),
keras.layers.Dense(3, activation='softmax')
])
* activation = 'relu' : Rectified Linear Unit은 sigmoid function의 Gradient Vanishing 문제해결을 위한 선형함수
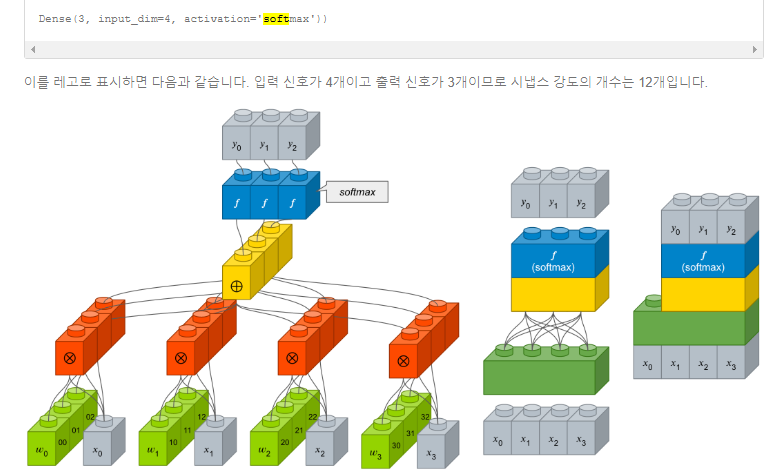
* activation='softmax' : 인공신경망이 내놓은 k개의 클래스 구분 결과를 확률처럼 해석하도록 만들어주는 함수
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])model.fit(train_x, train_y, epochs=200, verbose=0)loss, acc = model.evaluate(test_x, test_y)
print("loss :", loss)
print("acc :", acc)
y_ = model.predict(test_x)
print(y_)
print(np.argmax(y_, axis=1)) # 가장 큰 클래스를 출력해주는 함수* np.argmax(y, axis=1) : 가장 큰 클래스를 출력해주는 함수
▶ loss categorical_crossentropy
* 2가지 crossentropy 사용 방법
- categorical_crossentropy
- sparse_categorical_crossentropy
* categorical_crossentropy
1. y의 값이 one hot encoding인 경우
1,0,0
0,1,0
0,0,1
2. 출력 레이어 설정
- model.add(Dense(3, activation="softmax")) # 출력 레이어
3. loss 설정
- model.compile(..., loss='categorical_crossentropy')
* sparse_categorical_crossentropy
1. y의 값이 one hot encoding인 경우
0
1
2
2. 출력 레이어 설정
- model.add(Dense(3, activation="softmax")) # 출력 레이어. 1이 아니라 클래스 수 3
3. loss 설정
- model.compile(..., loss='sparse_categorical_crossentropy')
▶ iris_dnn with category index
아래의 코드는 iris_dnn_and_optimizer.ipynb의 코드를 기반으로 한다.
!wget https://raw.githubusercontent.com/dhrim/oss_university/master/material/iris_with_category_index.csviris = pd.read_csv("iris_with_category_index.csv")
iris.head()
data = iris.to_numpy()
print(data.shape)
print(data[:5])x = data[:,:4]
y = data[:,4:]
split_index = 100
train_x, test_x = x[:split_index], x[split_index:]
train_y, test_y = y[:split_index], y[split_index:]
print(train_x.shape)
print(train_y.shape)
print(test_x.shape)
print(test_y.shape)model = keras.Sequential()
model.add(Dense(10, activation='relu', input_shape=(4,)))
model.add(Dense(10, activation='relu'))
model.add(Dense(3, activation="softmax")) # 1이 아니고 클래스 수 3이다
# model.compile(optimizer="SGD", loss="categorical_crossentropy", metrics=["accuracy"])
model.compile(optimizer="SGD", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
model.summary()
model.fit(train_x, train_y, epochs=1000, verbose=0, batch_size=20)
loss, acc = model.evaluate(test_x, test_y)
print("loss=", loss)
print("acc=", acc)* loss="sparse_categorical_crossentropy" : 손실을 사용할 때 대상은 정수 대상이여야 한다. (다중분류손실함수)
* metrics=["accuracy"] : 정확성을 기준을 평가
ㄴ metrics : 평가기준
y_ = model.predict(test_x)
print(y_)
print(np.argmax(y_, axis=1))'Deep learning > Code' 카테고리의 다른 글
| object_detection_yolo_darknet (0) | 2020.01.22 |
|---|---|
| 2020_01_22 VGG16 (0) | 2020.01.22 |
| 2020_01_22 CIFAR10 (0) | 2020.01.22 |
| 2020_01_21 CNN (0) | 2020.01.21 |
| 2020_01_20 DL(Keras) (0) | 2020.01.20 |